[LeetCode] 每日一题 July 21~31
- July 21 - 剑指 Offer 52. 两个链表的第一个公共节点;
- July 22 - 138. 复制带随机指针的链表;
July 21 - 剑指 Offer 52. 两个链表的第一个公共节点
描述
输入两个链表,找出它们的第一个公共节点。
样例
示例1:
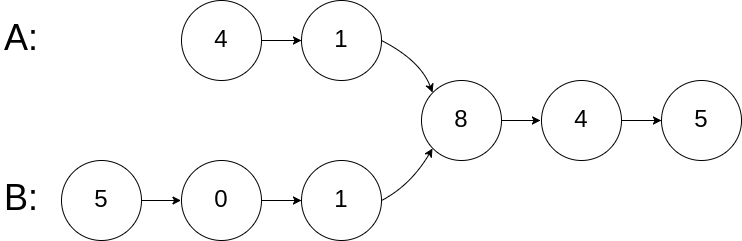
1 | |
示例2:
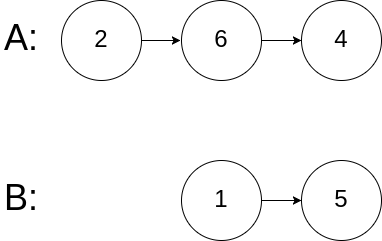
1 | |
思路
双指针法
使用双指针的方法,可以将空间复杂度降至 O(1)。
只有当链表 headA 和 headB 都不为空时,两个链表才可能相交。因此首先判断链表 headA 和 headB 是否为空,如果其中至少有一个链表为空,则两个链表一定不相交,返回 null。
当链表 headA 和 headB 都不为空时,创建两个指针 pA 和 pB,初始时分别指向两个链表的头节点 headA 和 headB,然后将两个指针依次遍历两个链表的每个节点。具体做法如下:
每步操作需要同时更新指针 pA 和 pB。
如果指针 pA 不为空,则将指针 pA 移到下一个节点;如果指针 pB 不为空,则将指针 pB 移到下一个节点。
如果指针 pA 为空,则将指针 pA 移到链表 headB 的头节点;如果指针 pB 为空,则将指针 pB 移到链表 headA 的头节点。
当指针 pA 和 pB 指向同一个节点或者都为空时,返回它们指向的节点或者 null。
下面提供双指针方法的正确性证明。考虑两种情况,第一种情况是两个链表相交,第二种情况是两个链表不相交。
情况一:两个链表相交
链表 headA 和 headB 的长度分别是 m 和 n。假设链表 headA 的不相交部分有 a 个节点,链表 headB 的不相交部分有 b 个节点,两个链表相交的部分有 c 个节点,则有 a+c=m,b+c=n。
如果 a=b,则两个指针会同时到达两个链表的第一个公共节点,此时返回两个链表的第一个公共节点;
如果 a!=b,则指针 pA 会遍历完链表 headA,指针 pB 会遍历完链表 headB,两个指针不会同时到达链表的尾节点,然后指针 pA 移到链表 headB 的头节点,指针 pB 移到链表 headA 的头节点,然后两个指针继续移动,在指针 pA 移动了 a+c+b 次、指针 pB 移动了 b+c+a 次之后,两个指针会同时到达两个链表的第一个公共节点,该节点也是两个指针第一次同时指向的节点,此时返回两个链表的第一个公共节点。
情况二:两个链表不相交
链表 headA 和 headB 的长度分别是 m 和 n。考虑当 m=n 和 m!=n 时,两个指针分别会如何移动:
如果 m=n,则两个指针会同时到达两个链表的尾节点,然后同时变成空值 null,此时返回 null;
如果 m!=n,则由于两个链表没有公共节点,两个指针也不会同时到达两个链表的尾节点,因此两个指针都会遍历完两个链表,在指针 pA 移动了 m+n 次、指针 pB 移动了 n+m 次之后,两个指针会同时变成空值 null,此时返回 null。
代码
1 | |
July 22 - 138. 复制带随机指针的链表
描述
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random –> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random –> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
- val:一个表示 Node.val 的整数。
- random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码只接受原链表的头节点 head 作为传入参数。
样例
示例1:
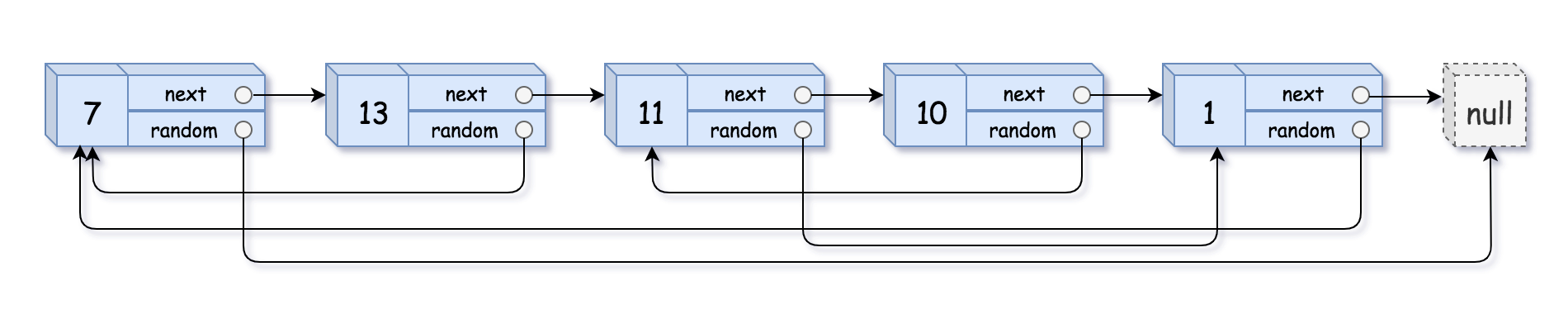
1 | |
示例2:

1 | |
示例3:

1 | |
示例4:
1 | |
思路
方法一:回溯 + 哈希表
本题要求我们对一个特殊的链表进行深拷贝。如果是普通链表,我们可以直接按照遍历的顺序创建链表节点。而本题中因为随机指针的存在,当我们拷贝节点时,「当前节点的随机指针指向的节点」可能还没创建,因此我们需要变换思路。一个可行方案是,我们利用回溯的方式,让每个节点的拷贝操作相互独立。对于当前节点,我们首先要进行拷贝,然后我们进行「当前节点的后继节点」和「当前节点的随机指针指向的节点」拷贝,拷贝完成后将创建的新节点的指针返回,即可完成当前节点的两指针的赋值。
具体地,我们用哈希表记录每一个节点对应新节点的创建情况。遍历该链表的过程中,我们检查「当前节点的后继节点」和「当前节点的随机指针指向的节点」的创建情况。如果这两个节点中的任何一个节点的新节点没有被创建,我们都立刻递归地进行创建。当我们拷贝完成,回溯到当前层时,我们即可完成当前节点的指针赋值。注意一个节点可能被多个其他节点指向,因此我们可能递归地多次尝试拷贝某个节点,为了防止重复拷贝,我们需要首先检查当前节点是否被拷贝过,如果已经拷贝过,我们可以直接从哈希表中取出拷贝后的节点的指针并返回即可。
在实际代码中,我们需要特别判断给定节点为空节点的情况。
时间复杂度:O(n),其中 n 是链表的长度。对于每个节点,我们至多访问其「后继节点」和「随机指针指向的节点」各一次,均摊每个点至多被访问两次。
空间复杂度:O(n),其中 n 是链表的长度。为哈希表的空间开销。
方法二:map
第一轮遍历构建旧链表和新链表的一一映射
第二轮遍历根据旧链表的next和random信息,补充新链表的next和random信息
时间复杂度:O(n),空间复杂度:O(n)
代码
1 | |
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!